Development Pipeline for the Rackspace Cloud Control Panel
21 Sep 2014 TweetForeword
The Cloud Control Panel at Rackspace has ~30 developers split into 8 subteams. All of them are expected to have the ability to modify any part of the system, however, each subteam has some type of specialized knowledge of the product or infrastructure. Our team has a CI/CD pipeline in which we deploy up to 10 times a day (every hour during business hours). This evolved from a pipeline where every merge triggered a deploy.
Development to Production?
Our pipeline is fairly standard in terms of what we want to happen from development to production. Branch, merge, test, and deploy. We use a private github repository. When a developer takes a story from the backlog they create a feature branch with git. The developer will add the feature and all appropriate unit, integration, and acceptance tests to that branch. During feature development they ask for feedback or a code review and a +1 means they are allowed to merge. This is important as all branches require a code review before merging. I want to define acceptance level testing as this is a term we use on our team for tests which use selenium to execute real scenarios a user would take in the browser working with the control panel using real upstream APIs.
Before merging developers run their branch against a builder with their latest hash. Branch builds are a series of jenkins jobs which do things like run all of the unit / integration tests, a subset of the acceptance tests and linting the code. If everything is good the build triggers a script which marks the branch as “ok to merge” with a checkmark on github. If it does not pass it gives it an X or “bad to merge” with a link to the failed job.
Our pipeline has had the same structure for several years, but evolved in how we used it. Merging code runs the same tasks as the branch builder and more. The additional tasks including compiling, creating a tarball as a distributable, and storing it as an artifact on jenkins. For brevity I will be referring to this as a “dist”. After the dist is created it triggers a deploy job sending this code to a preprod, staging, and preview environment1. Preprod matches production exactly. Staging uses API’s that upstream teams have deployed to their preprod environment but not production. Preview is the same as preprod but, with all feature flags flipped on. At this point our acceptance testing suite kicks off and developers validate that they didn’t break anything in the lower environments. If everything is considered good that dist is deployed to production.
The Early Days
In the early days of the Cloud Control Panel our team hovered around ~15 developers. As I mentioned earlier merging triggered deploying to all 3 lower environments and running acceptance level tests against them. This worked okay until we started to grow. As we had more developers join the team we realized that our 30 minute deploy process was taking several hours and even had the possibility of deploying unverified code. How did this happen? As I mentioned previously each merge deployed to the same environment. When we had 5 people merge this would trigger 5 deploys and 5 runs of acceptance level testing. The first round of acceptance tests would be halfway through, but the third merge of code would be on the environment which meant that we don’t know if the tests completed against a single environment. Developer 1 would deploy to production thinking all the tests were green when, in fact, a defect had slipped through.
We could have done all these tasks in serial and blocked lower environment deploys on a per merge basis, but this didn’t fit our “deploy to production fast” workflow. With five people this would take the fifth person 2.5 hours (30 minutes per merge) to get to production. There are also issues when the 3rd person introduces a defect, but doesn’t find out until an hour later (not fast feedback) so now the people in line have to wait for a revert or fix. We wanted to get code out there faster. It provides a real benefit for our team and customers to see features, changes, and fixes quickly.
It was a chaotic environment. Merging became an arduous task. I had no idea how long it would take me to get to production and I had to guess as to what code was on the lower environments and constantly watch for other merges coming in. This did not make for a happy developer. What came about from this chaos was an idea called the bus station.
The Bus Station
When a developer merges we take that code all the way to its built dist. Every hour we deploy to the lower environments with the latest good dist that was built. We called this a bus. At this point the acceptance tests run against the lower environments, which could contain several merges from different developers. The developers on that bus will verify their changes as good or bad and it gets sent off to production. This provides developers with a very structured time period in which their code will be deployed.
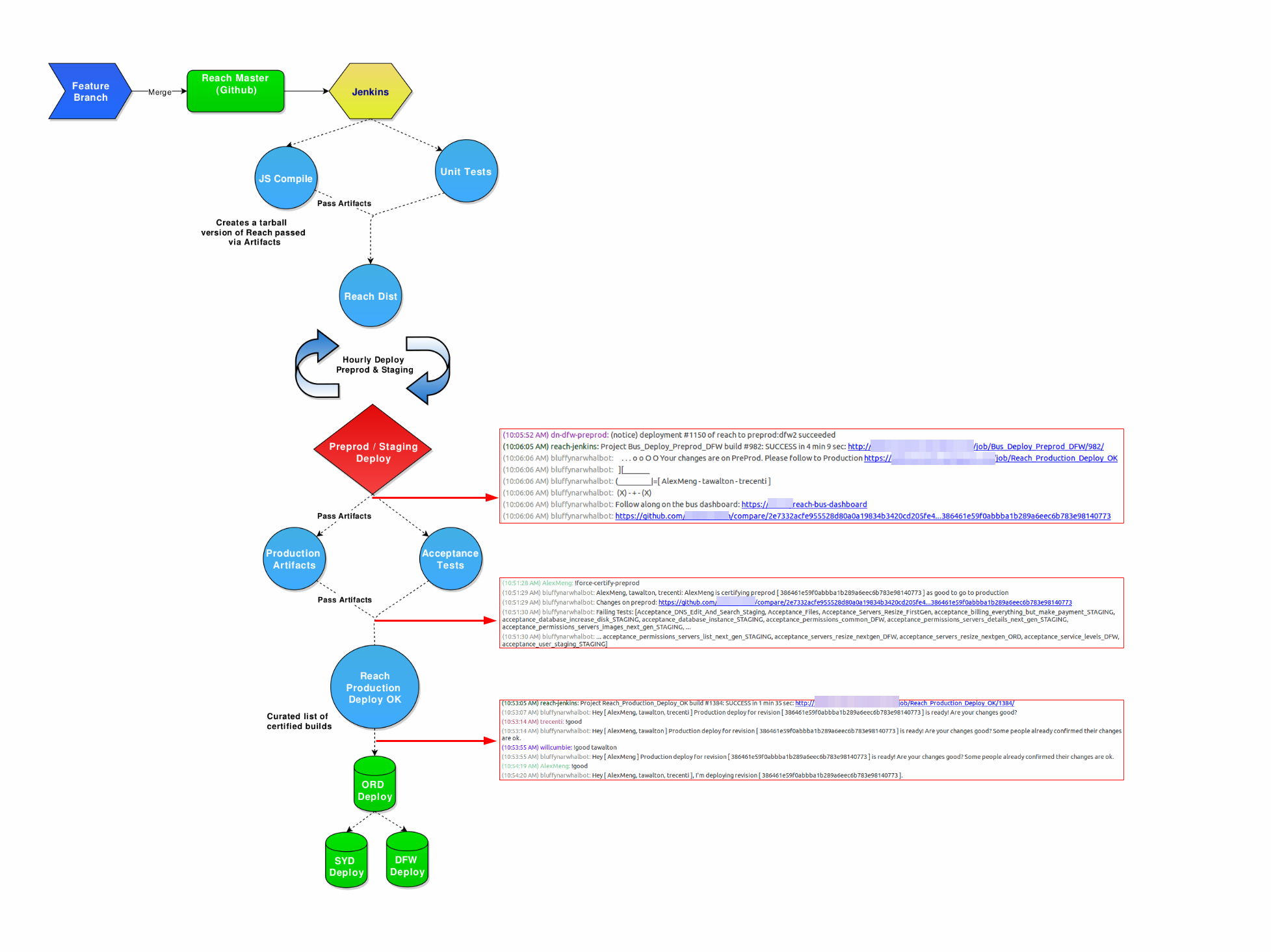
Now, this system isn’t perfect either and has some drawbacks. Having a dist that takes too long to build right before the next bus? Wait another hour. Someone introduces a defect which affects the whole bus? Wait another hour.
This system, however, has created an organized process for our team. I have a better idea for knowing when code will be deployed. Other people on the team can help spot defects as they are working together to deploy rather than individually. The team has built a great deal of tooling around the bus station to interact with our IRC channel and dashboards for dispersing knowledge about the state of a current deploy
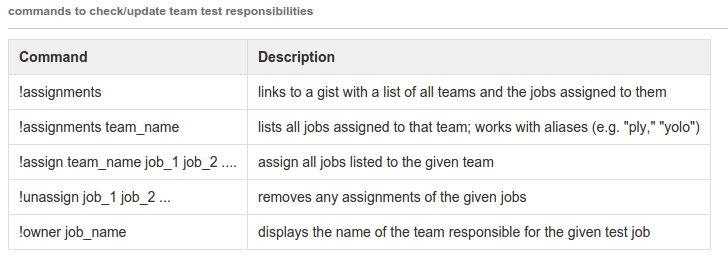
Tooling - IRC Commands
We have a custom IRC bot with several useful commands to interact with deploys.
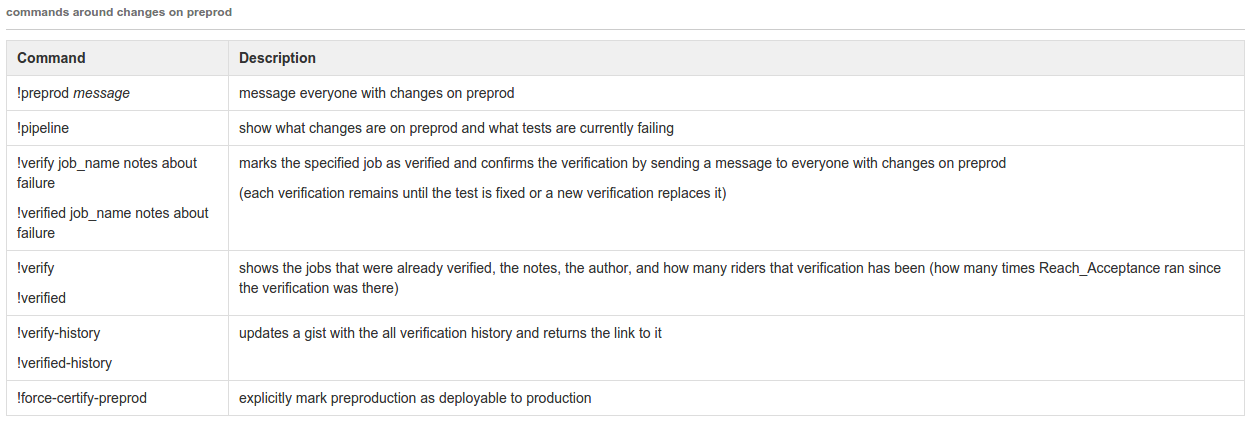
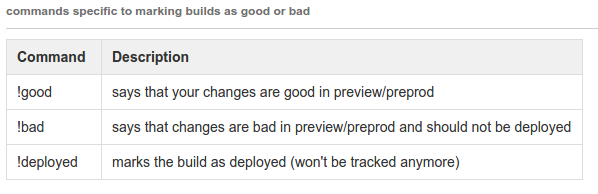
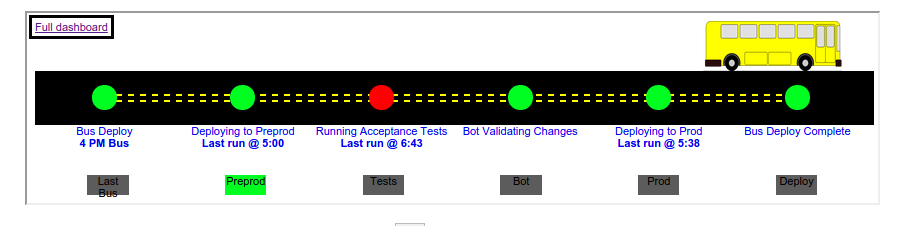
Tooling - Dashboards
Several dashboards have been created for understanding where the current bus is at in the pipeline and what the current health of our acceptance level tests are.
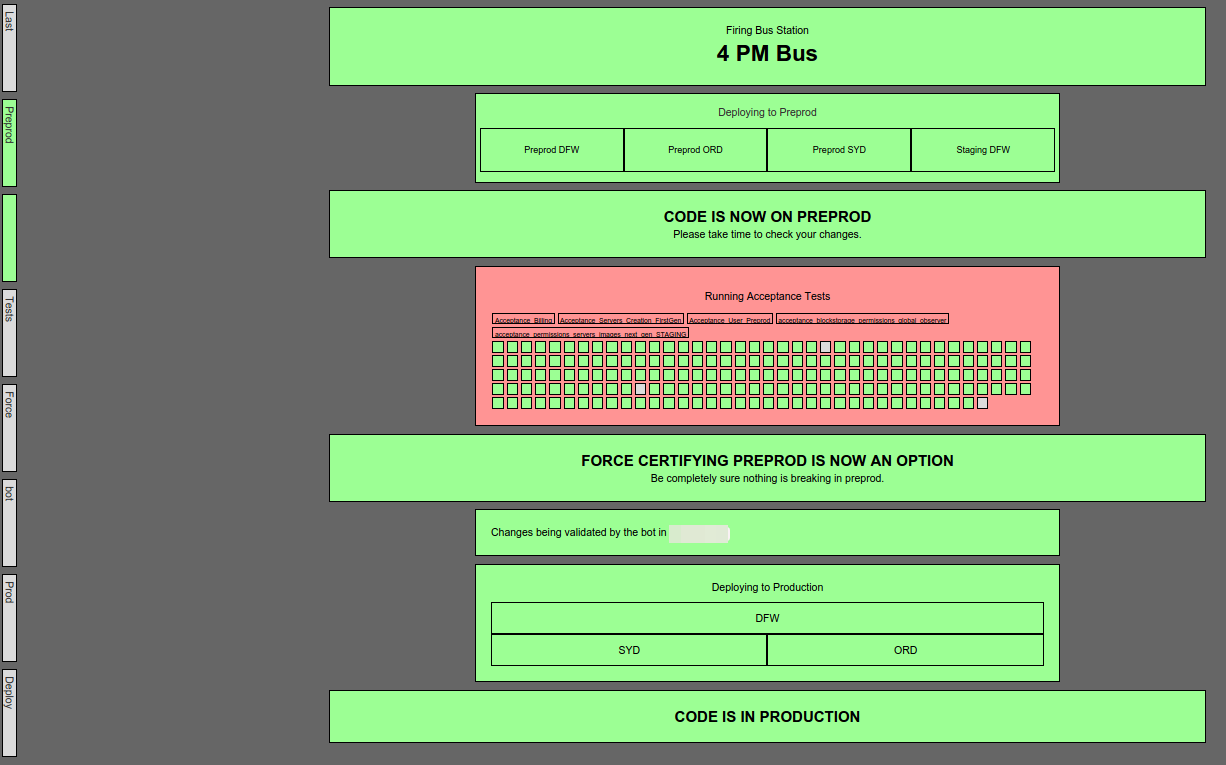

Not All Pipelines Are Created Equal
The above tooling has all been built around our large team size. Not all continuous delivery pipelines have to follow what we have done, and I would actually argue most shouldn’t. We have another service which has only ~6 contributors and 1 or 2 merges a day. That project has a much more manual and rudimentary deploy scheme where team members have to communicate with each other before merging to ensure they don’t break the pipeline on deploys. This pipeline took less than a week to setup, compared to our main project above where individual team members have built up dashboards and irc commands over several years.
The Future
This isn’t the end for our deployment pipeline. I would ideally like to see our individual applications for the control panel deployed independently. Currently we tarball our whole repo at once for deploys. Our javascript/css upload to cdn, python/django web backend, twisted and node.js services should all be separate deploy pipelines with their tests ran individually so that they can be deployed faster and with less dependencies. There are still many challenges ahead for us to reach this level, but doing so provides benefits to scaling our team and application.