Team workflow using littlechef to manage infrastructure
21 Nov 2014 TweetLittlechef is a library allowing one to use chef without a centralized server orchestrating configuration management. It simplifies the testing and deployment model for managing servers by removing a layer from the stack. What this does is let you provision servers using your cli or programmatically in a similar fashion to ansible.
Recently I was snooping on another team who was doing some work to get chef-solo working in their infrastructure and made a brief comment about littlechef to see if they were moving to it. They made two comments
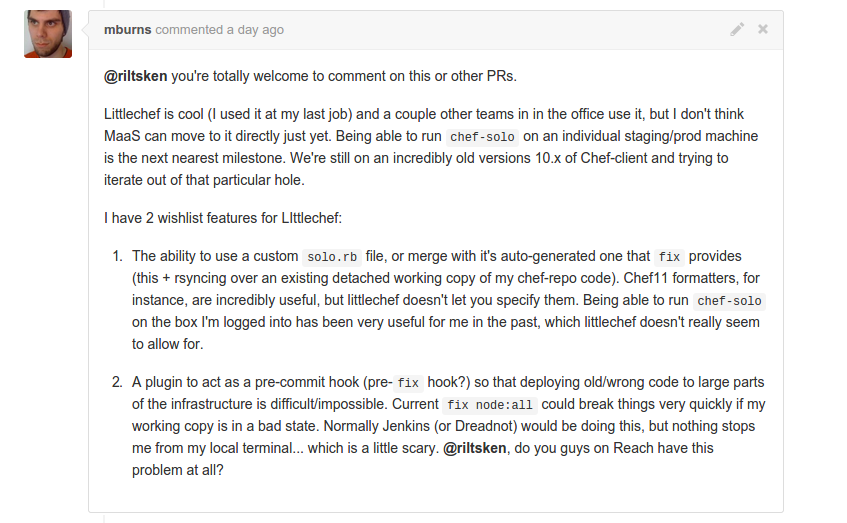
What I took from the above were essentially questions about our workflow with littlechef. How can we test our changes? How do we know our changes will actually work? How do we not mess up real environments? Below is generally how our team makes changes with chef using littlechef. This works for a team of ~25 developers where 3-4 people are focused mostly on chef throughout the day. We manage ~200+ nodes.
Given that we are attempting to change a recipe that affects all web nodes:
- Write unit test with chefspec expecting this change.
- Run
fixagainst a specific web node in our test environment. Ensure that the run did not error. This probably looks likefix node:web-n01.test.mydns.com - SSH on to that specific web node and make sure our expected change occurred
- Run a branch build on jenkins which does chefspec, rubocop, and json linting and gives a green checkmark on your github pull request.
If this change includes adding a new community cookbook there is an extra step required which is sync the cookbooks locally before attempting to provision that node with littlechef.
If this change is required on a group of nodes this is still possible and again would still take place in the test environment.
fix --env=test_dfw nodes_with_role:cassandra
Looking at the above there is actually a region in our environment name. We maintain several different datacenters per environment and we scope all of our fix commands with the specific region environment. If you want to deploy to all environments you could just run several fix commands in-tandem or one after the other.
It is important to use the environment attribute when using nodes_with_role so if they are not specific enough an accidental provision of other environments does not happen.
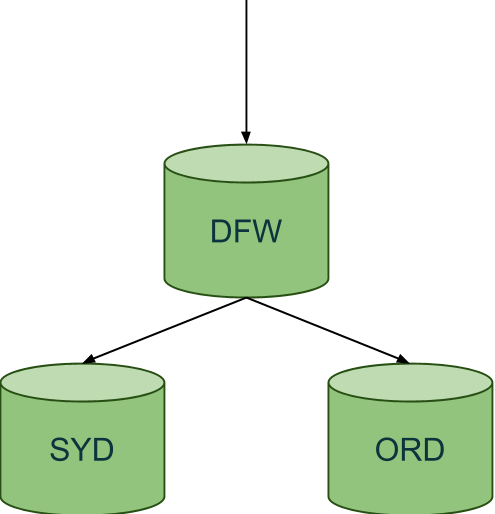
Going back to that pull request where we had a green checkmark. Merging that branch into master doesn’t do anything immediately (although it could). Currently we have it setup so that after you merge into master you run a job on jenkins that deploys to our lower environments (staging, preprod, and preview). The actual deploys are a series of scripts that build up a runlist per environment. We use a tool called Dreadnot to execute the runlist, but it could just as easily be a series of jenkins jobs. Here is an example of a deploy to our preprod sydney environment which runs in parallel with our staging and preview deploys. Each environment typically has three datacenters ORD, SYD, and DFW.
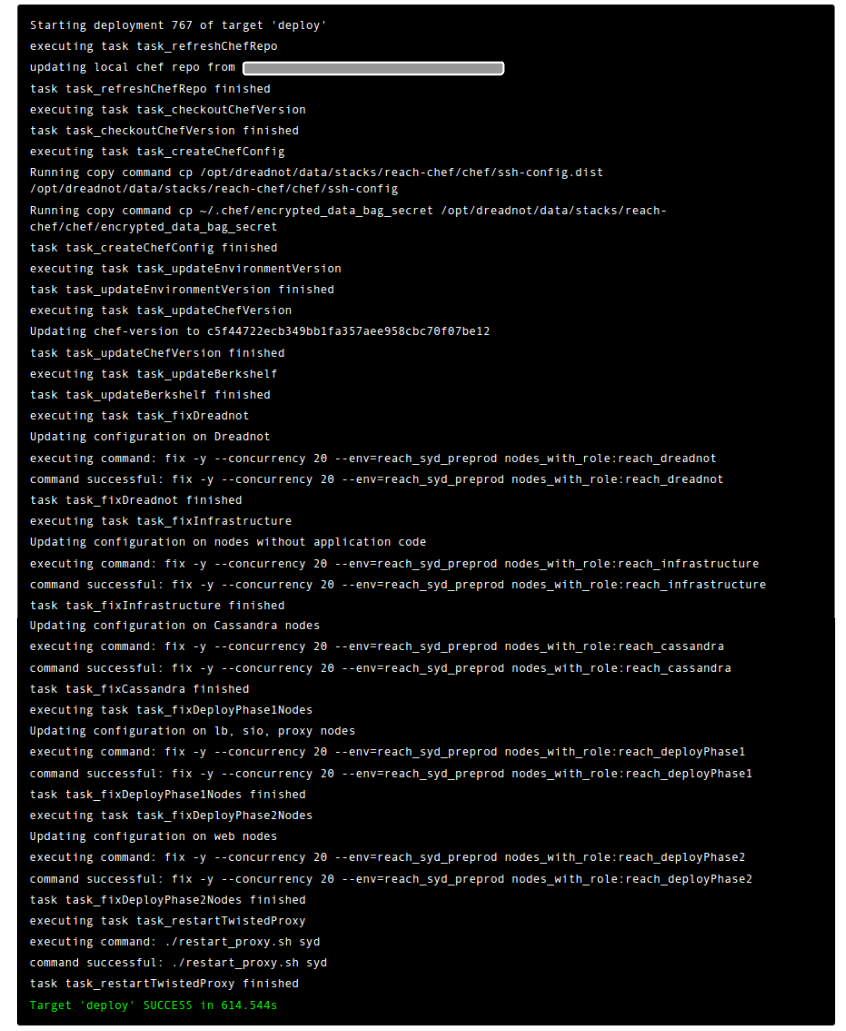
After deploying to all lower environments we typically verify that our expected change happened and begin deploying to production. Production deploys are similar to our lower environments with one key difference. The order of environment deploys first goes to our inactive standby environment, and after completion goes on to our active production environments. We do not have to do a failover to do a successful deploy.
Provisioning or creating new nodes
To provision or create new nodes with littlechef a previous coworker Dave H King made a library (Littlechef-Rackspace) to make this really easy on Rackspace. It allows us to run a single command which brings up a node in our environment and runs plugins after it is created. The plugins we currently run install chef via omnibus and creates the node json file with extra information specific to how we setup our environment (private ips, labeling, environment). After the node is active and plugins have been ran it can take a runlist to configure the node as needed and add it to the node.json file.
fix-rackspace create \
--username <username> \
--key <api_key> \
--region <region> \
--image <image_id> \
--flavor <flavor_id> \
--name "web-n01.preprod.dfw" \
--public-key <public_key_file> \
--private-key <private_key_file> \
--runlist "role[base],role[reach_base],role[reach_dfw_preprod],role[web]" \
--plugins "omnibus_install_11, bootstrap" \
--post-plugins "add_role"
All of the above can be run in one command, but it can be difficult to remember all of the configuration values needed to add a new node to our environment. The library has an added bonus of being able to use yaml templates which greatly simplify the process of what plugins to use and what runlists we need to add to configure the node. Our plugins are here and our post plugins after the runlist has been ran are here
image: {imageid-placeholder}
flavor: {flavorid-placeholder}
plugins:
- omnibus_install_11
- bootstrap
post-plugins: add_role
use_opscode_chef: false
templates:
base:
runlist:
- "role[base]"
- "role[reach_base]"
networks:
- 00000000-0000-0000-0000-000000000000
- 11111111-1111-1111-1111-111111111111
preprod-dfw:
region: dfw
environment: reach_dfw_preprod
runlist:
- "role[reach_dfw_preprod]"
networks:
- 0f4c20c1-4c91-8a69-900d-44ff1fdd6fbd
secrets-file: secrets-reachpreprod.cfg
web:
runlist:
- "role[reach_web]"
And the new resulting command to spin up a web node in the dfw region for our preprod environment
fix-rackspace create --name web-n01.preprod.dfw base preprod-dfw web