Making runbooks more useful by exposing them through monitoring
19 Apr 2014 TweetIn the Server Message Of The Day (MOTD) post, I mentioned the importance of sharing tribal knowledge across teams on fixing infrastructure issues. When any of our monitoring alarms kick off, any team member should be equipped to take action on the alarm, but we operate with so many different technologies that no one person could possibly be an expert in all of them. Most operations teams create runbooks for common tasks, but we took it one step further and created runbooks for every alarm in our system. They don’t exactly cover every possible reason for an alarm triggering, but will always help to provide context for someone that doesn’t regularly deal with that subsystem.
Our runbooks are composed of the node’s title and definition, its role in the system, and important config files. After that block is a section for all the system’s monitoring alerts and what actions you can take to investigate or fix them. This is one of the runbooks for Cassandra:
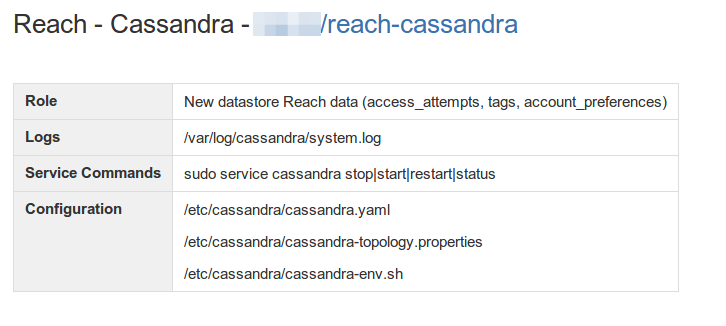

Triggered alarms link the runbook
We use IRC for team communication since we’re all distributed. The alerts will stream into the channel via bot with direct links to the runbooks and every triggered alarm. While we do have a proper escalation path through PagerDuty, this keeps the whole team aware of issues and gives anyone an easy path for investigation and action.
